
Convolutional Neural Networks (CNNs) have their roots in the field of computer vision, dating back to the 1980s. The first successful application of CNNs to computer vision was the LeNet-5 architecture, developed by Yann LeCun et al. in 1998. This architecture used a series of convolutional layers followed by fully connected layers to classify handwritten digits.
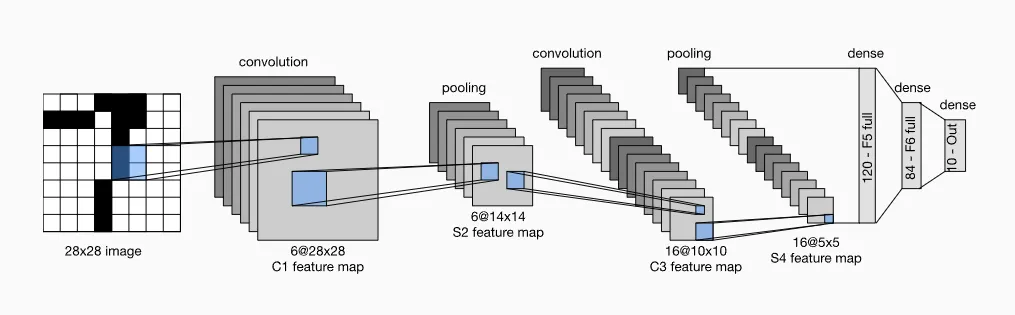
In the years that followed, CNNs continued to be refined and applied to a wide range of computer vision tasks, including object detection, image segmentation, and facial recognition. In 2012, a team of researchers led by Alex Krizhevsky achieved a breakthrough in image classification by using a deep CNN architecture, called AlexNet, to win the ImageNet Large Scale Visual Recognition Challenge.
The birth of Recurrent Neural Networks (RNNs)
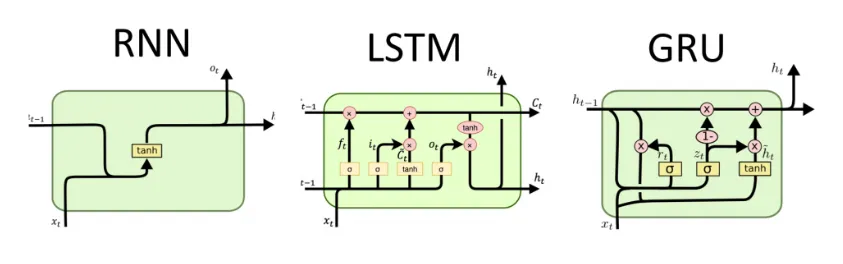
In the late 1990s, a new type of RNN called Long Short-Term Memory (LSTM) was introduced by Hochreiter and Schmidhuber. LSTMs addressed the vanishing gradient problem by using a gating mechanism to control the flow of information through the network, allowing it to selectively remember or forget information from previous timesteps.
While CNNs have been highly successful in the domain of computer vision, they are not well-suited for processing text data. The reason for this is that text data is inherently sequential, with each word or character depending on the ones that came before it. CNNs, on the other hand, are designed to operate on fixed-size inputs and are not naturally suited for processing variable-length sequences.
To process text data, researchers have instead turned to RNNs and their variants, such as LSTMs and Gated Recurrent Units (GRUs). These models are designed to handle sequential data and are able to capture long-term dependencies in the data, making them well-suited for a wide range of natural language processing tasks.
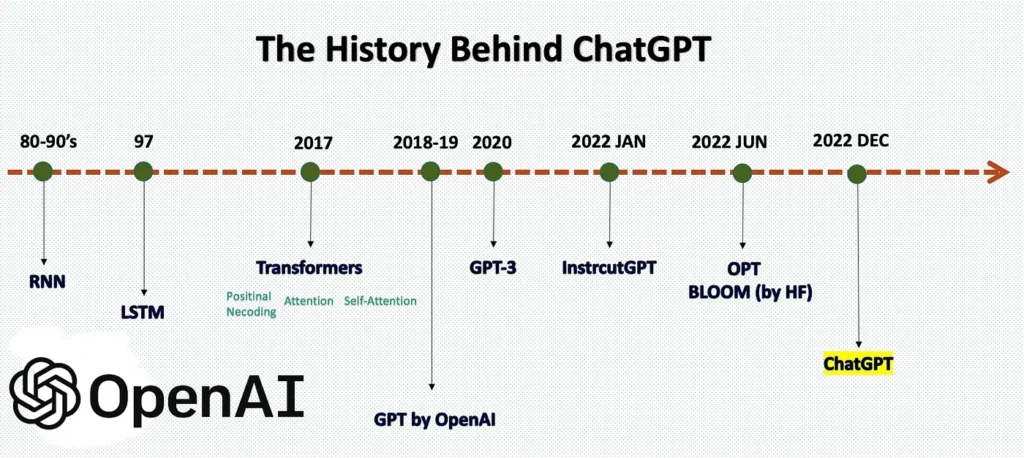
The Big Picture
The following Image Indicates the major landmarks and the introduced architectures in each of the phases. Now we saw the Birth of RNNs and Next we going to look around the Game Changer of entire deep-learning
The Man, The Myth, The Legend, The Transformers
The Transformer architecture was introduced as a solution to some of the limitations of traditional sequence-to-sequence (Seq2Seq) models in natural language processing (NLP). Seq2Seq models are a class of neural networks that are used to map variable-length input sequences to variable-length output sequences. They consist of two components: an encoder that processes the input sequence and a decoder that generates the output sequence.
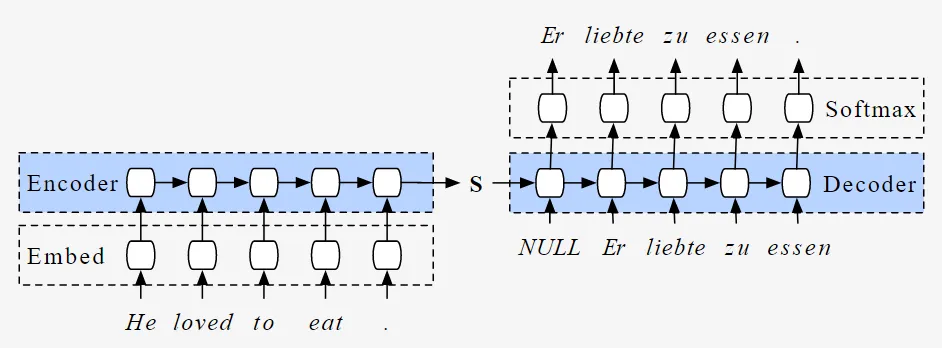
One of the most popular applications of Seq2Seq models is neural machine translation (NMT). NMT systems using Seq2Seq models were able to achieve impressive results in translating text from one language to another. However, these models had some limitations that made them less effective for certain types of translation tasks.
One of the main limitations of Seq2Seq models is that they rely on fixed-length vectors to represent the input and output sequences. This can be a problem when dealing with long sequences, as it can be difficult to capture all of the relevant information in a single vector. In addition, Seq2Seq models have difficulty handling long-term dependencies between the input and output sequences, which can result in translations that are overly literal or contain grammatical errors.
The Transformer architecture was introduced as a solution to these limitations. The key innovation in the Transformer architecture is the self-attention mechanism, which allows the model to weigh the importance of different parts of the input sequence when making predictions. This mechanism enables the model to capture long-range dependencies and make better use of contextual information.
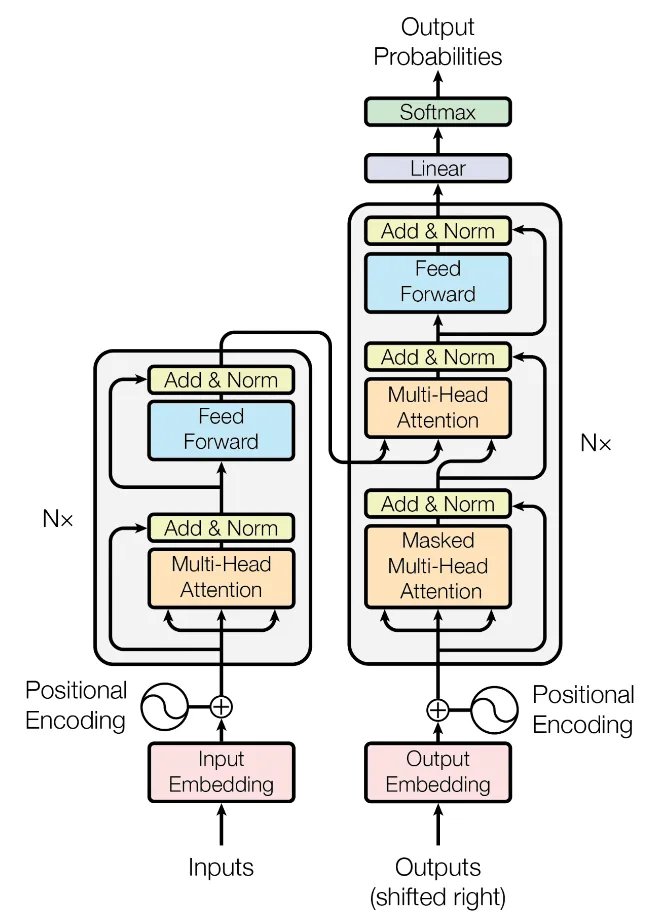
When applied to NMT, the Transformer architecture achieved significant improvements over Seq2Seq models. This was due in part to the self-attention mechanism, which allowed the model to better capture the context of each word in the input sentence. The Transformer also introduced a novel technique called positional encoding, which allows the model to encode the position of each word in the input sequence, further improving its ability to capture long-range dependencies.
Overall, while Seq2Seq models were successful in many NLP tasks, they were not well-suited for neural machine translation, particularly for longer sequences. The Transformer architecture addressed many of the limitations of Seq2Seq models and enabled significant improvements in NMT performance.
In the next part, we are going to see the Transformer Architecture in more detail and different Transformer variants including BERT, and T5.
Copyright © Isuru Alagiyawanna. All rights reserved. This article was originally published on Medium and is reproduced here with permission.

